

이 포스팅은 Kaggle의 California Housing Prices 문제 풀이를 따라 연습한 글입니다.
INTRO
해당 Competition은 1990년 캘리포니아 인구조사 데이터인 캘리포니아 주택 가격(California Housing Prices) 데이터셋을 사용하며, 학습을 통해 주택 가격(median)을 예측하는 문제입니다.
Step 1. Load in the data
1.1 패키지 및 데이터 불러오기
- 변수 설명
longitude: 경도latitude: 위도housing_median_age: 주택 나이 (중앙값)total_rooms: 전체 방 수total_bedrooms: 전체 침실 수population: 인구households: 세대median_income: 소득(중앙값)median_house_value: 주택 가치(중앙값)ocean_proximity: 바다 근접도
library(tidyverse) # 데이터 처리 패키지 모음
library(reshape2) # 데이터 조작 패키지(Wide-format 또는 Long-format)
housing <- read.csv("../input/housing.csv") # 데이터 불러오기1.2 실제 데이터 확인
head(housing)
## longitude latitude housing_median_age total_rooms total_bedrooms population households median_income
## 1 -122.23 37.88 41 880 129 322 126 8.3252
## 2 -122.22 37.86 21 7099 1106 2401 1138 8.3014
## 3 -122.24 37.85 52 1467 190 496 177 7.2574
## 4 -122.25 37.85 52 1274 235 558 219 5.6431
## 5 -122.25 37.85 52 1627 280 565 259 3.8462
## 6 -122.25 37.85 52 919 213 413 193 4.0368
## median_house_value ocean_proximity
## 1 452600 NEAR BAY
## 2 358500 NEAR BAY
## 3 352100 NEAR BAY
## 4 341300 NEAR BAY
## 5 342200 NEAR BAY
## 6 269700 NEAR BAY1.3 변수 요약 정보 확인
summary(housing)
## longitude latitude housing_median_age total_rooms total_bedrooms population
## Min. :-124.3 Min. :32.54 Min. : 1.00 Min. : 2 Min. : 1.0 Min. : 3
## 1st Qu.:-121.8 1st Qu.:33.93 1st Qu.:18.00 1st Qu.: 1448 1st Qu.: 296.0 1st Qu.: 787
## Median :-118.5 Median :34.26 Median :29.00 Median : 2127 Median : 435.0 Median : 1166
## Mean :-119.6 Mean :35.63 Mean :28.64 Mean : 2636 Mean : 537.9 Mean : 1425
## 3rd Qu.:-118.0 3rd Qu.:37.71 3rd Qu.:37.00 3rd Qu.: 3148 3rd Qu.: 647.0 3rd Qu.: 1725
## Max. :-114.3 Max. :41.95 Max. :52.00 Max. :39320 Max. :6445.0 Max. :35682
## NA's :207
## households median_income median_house_value ocean_proximity
## Min. : 1.0 Min. : 0.4999 Min. : 14999 <1H OCEAN :9136
## 1st Qu.: 280.0 1st Qu.: 2.5634 1st Qu.:119600 INLAND :6551
## Median : 409.0 Median : 3.5348 Median :179700 ISLAND : 5
## Mean : 499.5 Mean : 3.8707 Mean :206856 NEAR BAY :2290
## 3rd Qu.: 605.0 3rd Qu.: 4.7432 3rd Qu.:264725 NEAR OCEAN:2658
## Max. :6082.0 Max. :15.0001 Max. :500001 summary 결과를 통해 아래와 같은 전처리 요건들을 확인할 수 있습니다.
total_bedrooms에 있는 207건의 결측값(NA) 처리가 필요합니다.ocean_proximity는 binary column으로 분리하여야 합니다. R의 대부분의 머신러닝 알고리즘들은 categorical 데이터를 single column으로 처리합니다. 그러나 여기서는 가장 작은 공통 분모에 맞춰 분할을 수행합니다.- 주어진 그룹에 있는 집에 대한 정확한 정의가 있을 수 있으므로
total_bedrooms와total_rooms를mean_number_bedrooms및mean_number_rooms열로 만들어야 합니다.
- 그래프 출력
par(mfrow=c(2,5)) # 출력 화면 분할
colnames(housing) # 컬럼명 확인
## [1] "longitude" "latitude" "housing_median_age" "total_rooms" "total_bedrooms"
## [6] "population" "households" "median_income" "median_house_value" "ocean_proximity"
ggplot(data = melt(housing), mapping = aes(x = value)) +
geom_histogram(bins = 30) + facet_wrap(~variable, scales = 'free_x')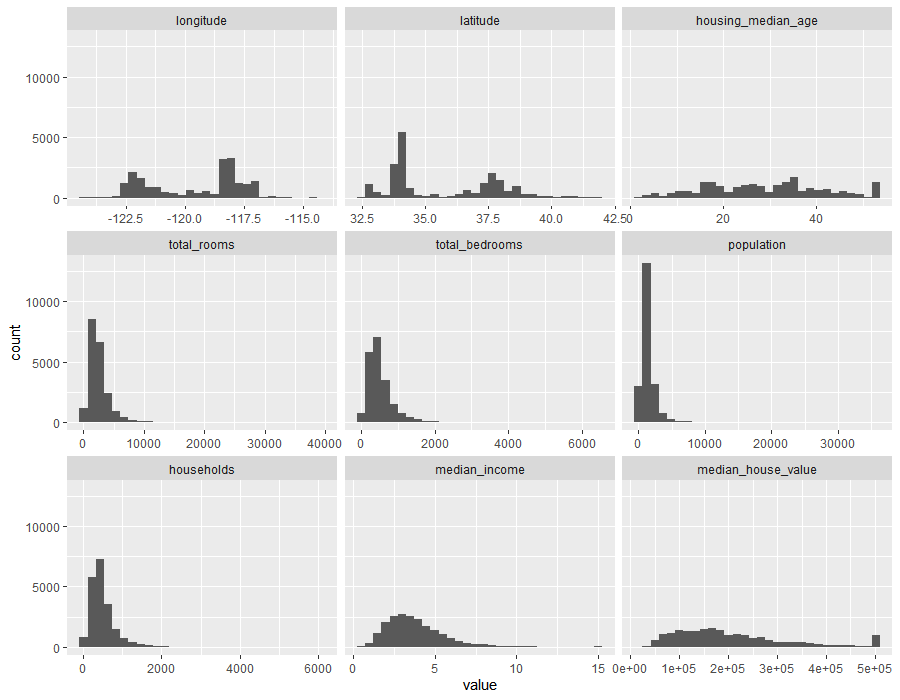
결과해석
ggplot 함수를 이용하여 housing변수의 데이터 분포를 시각적으로 확인하였습니다.
이 결과를 통해 몇가지 알 수 있는 정보가 있습니다.
housing_median_age는 오래된 주택이 있는 주택 블록이 있습니다.median_house_value는 histogram의 가장 오른쪽 지점에 특이한 블럭이 보입니다. bay area에는 500,000 이상의 가치가 있는 주택이 있습니다. 심지어 이 데이터 수집된 90년대에도 마찬가지 입니다.- non-tree 기반의 방법을 적용하기 위해 데이터들을 표준화 해야 합니다. 일부 변수의 범위는 0~10 이고 다른 변수는 500,000 입니다.
- 주택 가격 중 상한가는 예측에 영향을 줄 수 있습니다. 상한값을 제거하고 신뢰성 있는 데이터로만 작업할 필요가 있습니다.
Step 2. Clean the data
2.1 결측값 처리(Impute missing value)
total_bedrooms컬럼의 결측값(missing values)들을 중앙값(median) 으로 채워줍니다.- 중앙값(median) 을 사용하는 이유는 평균(mean) 보다 극단값(extreme outliers)에 덜 민감하기 때문입니다.
housing$total_bedrooms[is.na(housing$total_bedrooms)] = median(housing$total_bedrooms , na.rm = TRUE)
# 변수 가공 : total -> mean
# total 값들은 mean 값으로 변경하여 분석에 활용합니다.
housing$mean_bedrooms = housing$total_bedrooms/housing$households
housing$mean_rooms = housing$total_rooms/housing$households
drops = c('total_bedrooms', 'total_rooms')
housing = housing[ , !(names(housing) %in% drops)]
# 결과 확인
head(housing)
## longitude latitude housing_median_age population households median_income median_house_value
## 1 -122.23 37.88 41 322 126 8.3252 452600
## 2 -122.22 37.86 21 2401 1138 8.3014 358500
## 3 -122.24 37.85 52 496 177 7.2574 352100
## 4 -122.25 37.85 52 558 219 5.6431 341300
## 5 -122.25 37.85 52 565 259 3.8462 342200
## 6 -122.25 37.85 52 413 193 4.0368 269700
## ocean_proximity mean_bedrooms mean_rooms
## 1 NEAR BAY 1.0238095 6.984127
## 2 NEAR BAY 0.9718805 6.238137
## 3 NEAR BAY 1.0734463 8.288136
## 4 NEAR BAY 1.0730594 5.817352
## 5 NEAR BAY 1.0810811 6.281853
## 6 NEAR BAY 1.1036269 4.7616582.2 범주형 변수 처리 (Turn categoricals into booleans)
categorical 데이터 처리는 아래 절차로 진행합니다. (One-hot encoding 처리)
ocean_proximity컬럼의 categories를 모두 리스트로 가져옵니다.- 모든 값이
0으로 채워진 새로운 datafream을 생성하되, 각 category는 개별 컬럼을 만들어 줍니다. for-loop문을 이용하여 실제 값의 해당 커럼을1로 업데이트 해줍니다.- 기존 컬럼(
ocean_proximity)을 dataframe에서 drop 시켜줍니다.
1. ocean_proximity컬럼의 categories를 모두 리스트로 가져옵니다.
categories = unique(housing$ocean_proximity)
#split the categories off
cat_housing = data.frame(ocean_proximity = housing$ocean_proximity)2. 모든 값이 0으로 채워진 새로운 datafream을 생성하되, 각 category는 개별 컬럼을 만들어 줍니다.
for(cat in categories){
cat_housing[,cat] = rep(0, times= nrow(cat_housing))
}
head(cat_housing) #see the new columns on the right
## ocean_proximity NEAR BAY <1H OCEAN INLAND NEAR OCEAN ISLAND
## 1 NEAR BAY 0 0 0 0 0
## 2 NEAR BAY 0 0 0 0 0
## 3 NEAR BAY 0 0 0 0 0
## 4 NEAR BAY 0 0 0 0 0
## 5 NEAR BAY 0 0 0 0 0
## 6 NEAR BAY 0 0 0 0 03. for-loop문을 이용하여 실제 값의 해당 커럼을 1로 업데이트 해줍니다.
for(i in 1:length(cat_housing$ocean_proximity)){
cat = as.character(cat_housing$ocean_proximity[i])
cat_housing[,cat][i] = 1
}
head(cat_housing)
## ocean_proximity NEAR BAY <1H OCEAN INLAND NEAR OCEAN ISLAND
## 1 NEAR BAY 1 0 0 0 0
## 2 NEAR BAY 1 0 0 0 0
## 3 NEAR BAY 1 0 0 0 0
## 4 NEAR BAY 1 0 0 0 0
## 5 NEAR BAY 1 0 0 0 0
## 6 NEAR BAY 1 0 0 0 04. 기존 컬럼(ocean_proximity)을 dataframe에서 drop 시켜줍니다.
cat_columns = names(cat_housing)
keep_columns = cat_columns[cat_columns != 'ocean_proximity']
cat_housing = select(cat_housing,one_of(keep_columns))
tail(cat_housing)
## NEAR BAY <1H OCEAN INLAND NEAR OCEAN ISLAND
## 20635 0 0 1 0 0
## 20636 0 0 1 0 0
## 20637 0 0 1 0 0
## 20638 0 0 1 0 0
## 20639 0 0 1 0 0
## 20640 0 0 1 0 0여기서는 범주형 변수 처리를 직접 하였으나 다양한 패키지에서 함수로 제공이 되고 있습니다.
관련 내용은 추후 업데이트 하도록 하겠습니다.
- R에서 범주형 변수 처리하기
2.3 수치형 변수 처리(Scale the numerical variables)
여기서는 예측 변수(y)인 median_house_value를 제외한 모든 수치 데이터를 조정합니다.
서포트 벡터 머신(Support Vector Machine, SVM)과 같은 모델 계수에 동일한 가중치(weight)가 부여되도록 x값의 크기가 조정되지만, y값의 크기는 학습 알고리즘에 동일한 방식으로 영향을 미치지 않습니다.
housing변수 컬럼 확인
colnames(housing)
## 'longitude' 'latitude' 'housing_median_age' 'population' 'households' 'median_income'
## 'median_house_value' 'ocean_proximity' 'mean_bedrooms' 'mean_rooms'- 수치형 변수 추출
앞단계(2.2)에서 처리한 명목형 변수(ocean_proximity)와 예측 변수(median_house_value)는 대상에서 제외시킵니다.
drops = c('ocean_proximity','median_house_value')
housing_num = housing[ , !(names(housing) %in% drops)]
head(housing_num)
## longitude latitude housing_median_age population households median_income mean_bedrooms mean_rooms
## 1 -122.23 37.88 41 322 126 8.3252 1.0238095 6.984127
## 2 -122.22 37.86 21 2401 1138 8.3014 0.9718805 6.238137
## 3 -122.24 37.85 52 496 177 7.2574 1.0734463 8.288136
## 4 -122.25 37.85 52 558 219 5.6431 1.0730594 5.817352
## 5 -122.25 37.85 52 565 259 3.8462 1.0810811 6.281853
## 6 -122.25 37.85 52 413 193 4.0368 1.1036269 4.761658- 데이터 표준화 (Standardzation)
수치형 변수만 추출된 housing_num를 표준화하기 위하여 scale함수를 사용합니다.
scaled_housing_num = scale(housing_num)
head(scaled_housing_num)
## longitude latitude housing_median_age population households median_income mean_bedrooms mean_rooms
## [1,] -1.327803 1.052523 0.9821189 -0.9744050 -0.9770092 2.34470896 -0.148510661 0.6285442
## [2,] -1.322812 1.043159 -0.6070042 0.8614180 1.6699206 2.33218146 -0.248535936 0.3270334
## [3,] -1.332794 1.038478 1.8561366 -0.8207575 -0.8436165 1.78265622 -0.052900657 1.1555925
## [4,] -1.337785 1.038478 1.8561366 -0.7660095 -0.7337637 0.93294491 -0.053646030 0.1569623
## [5,] -1.337785 1.038478 1.8561366 -0.7598283 -0.6291419 -0.01288068 -0.038194658 0.3447024
## [6,] -1.337785 1.038478 1.8561366 -0.8940491 -0.8017678 0.08744452 0.005232996 -0.26972312.4 가공 변수 합치기(Merge the altered numerical and categorical data)
위에서 처리한 범주형 변수(cat_housing), 수치형 변수(scaled_housing_num), 예측 변수(median_house_house)를 컬럼 기준으로 합쳐줍니다.
cleaned_housing = cbind(cat_housing, scaled_housing_num, median_house_value=housing$median_house_value)
head(cleaned_housing)
## NEAR BAY <1H OCEAN INLAND NEAR OCEAN ISLAND longitude latitude housing_median_age population households
## 1 1 0 0 0 0 -1.327803 1.052523 0.9821189 -0.9744050 -0.9770092
## 2 1 0 0 0 0 -1.322812 1.043159 -0.6070042 0.8614180 1.6699206
## 3 1 0 0 0 0 -1.332794 1.038478 1.8561366 -0.8207575 -0.8436165
## 4 1 0 0 0 0 -1.337785 1.038478 1.8561366 -0.7660095 -0.7337637
## 5 1 0 0 0 0 -1.337785 1.038478 1.8561366 -0.7598283 -0.6291419
## 6 1 0 0 0 0 -1.337785 1.038478 1.8561366 -0.8940491 -0.8017678
## median_income mean_bedrooms mean_rooms median_house_value
## 1 2.34470896 -0.148510661 0.6285442 452600
## 2 2.33218146 -0.248535936 0.3270334 358500
## 3 1.78265622 -0.052900657 1.1555925 352100
## 4 0.93294491 -0.053646030 0.1569623 341300
## 5 -0.01288068 -0.038194658 0.3447024 342200
## 6 0.08744452 0.005232996 -0.2697231 269700Step 3. 검증 데이터 만들기(Create a test set of data)
이번 단계에서는 전체 데이터에서 학습 데이터(train set)와 검증 데이터(test set)를 분리합니다.
검증 데이터는 학습된 모델의 평가에만 사용되며, 학습/검증 데이터 분리를 통해 예측 결과의 객관성을 확보할 수 있습니다.
- 데이터 추출에는
sample함수를 이용하였으며,train(80%),test(20%)로 분리합니다.
set.seed(1738) # Set a random seed so that same sample can be reproduced in future runs
sample = sample.int(n = nrow(cleaned_housing), size = floor(.8*nrow(cleaned_housing)), replace = F)
train = cleaned_housing[sample, ] #just the samples
test = cleaned_housing[-sample, ] #everything but the samples- 분리된 데이터에 대한 정합성 검토
# 랜덤 추출 확인 : 첫 열의 인덱스(index) 번호 확인
head(train)
## NEAR BAY <1H OCEAN INLAND NEAR OCEAN ISLAND longitude latitude housing_median_age population
## 4975 0 1 0 0 0 0.6437155 -0.7639971 1.0615750 -0.4728430
## 13918 0 0 1 0 0 1.7567501 -0.7078161 -0.7659165 -1.1262865
## 9020 0 0 0 1 0 0.3941562 -0.6890891 -1.5604781 10.1085264
## 2900 0 0 1 0 0 0.2793589 -0.1225970 0.5053819 -0.8375351
## 2764 0 0 1 0 0 1.8416002 -1.2649446 -1.0837411 -1.2137066
## 5786 0 1 0 0 0 0.6586891 -0.6890891 -1.1631973 0.2256351
## households median_income mean_bedrooms mean_rooms median_house_value
## 4975 -0.6605285 -1.36479701 0.09416648 -0.79519952 112500
## 13918 -1.1600972 -0.39249525 0.11519417 -0.02182537 65600
## 9020 8.9751328 2.18074620 -0.11499230 0.93189653 399200
## 2900 -1.1993304 -1.03071303 -0.47625410 -1.01131583 47500
## 2764 -1.2542568 0.07902268 2.59860572 2.00915618 32500
## 5786 1.0604990 0.01828013 -0.10923682 -0.54183837 200000- 데이터 수 확인 :
nrow함수를 이용하여 변수별 행(row) 수 비교
nrow(train) + nrow(test) == nrow(cleaned_housing)
## [1] TRUEStep 4. 예측 모델 검증(Test some predictive models)
4.1 Simple linear model
간단한 선형 모형 테스트를 위해 아래 3개 변수를 선택하여 분석에 적용합니다.
- 소득(중앙값) :
median_income - 방 수(평균값) :
mean_rooms - 인구 :
population
또한, 모델의 과적합(overfit) 문제를 피하기 위해 cv.glm함수를 이용하여 교차 검증(k_fold)를 수행하며, 여기서는 모델 테스트에 전처리된 데이터 자체를 사용합니다.
library('boot')
# ?cv.glm # note the K option for K fold cross validation
glm_house = glm(median_house_value~median_income+mean_rooms+population, data=cleaned_housing)
k_fold_cv_error = cv.glm(cleaned_housing , glm_house, K=5)
# 첫 번째 성분은 예측 오차의 원시 교차 검증 추정치 입니다. 두 번째 구성 요소는 조정된 교차 검증 추정치 입니다.
k_fold_cv_error$delta
## [1] 6946162249 6942675168
glm_cv_rmse = sqrt(k_fold_cv_error$delta)[1]
glm_cv_rmse #off by about $83,000... it is a start
## [1] 83343.64
names(glm_house) #what parts of the model are callable?
## [1] "coefficients" "residuals" "fitted.values" "effects" "R"
## [6] "rank" "qr" "family" "linear.predictors" "deviance"
## [11] "aic" "null.deviance" "iter" "weights" "prior.weights"
## [16] "df.residual" "df.null" "y" "converged" "boundary"
## [21] "model" "call" "formula" "terms" "data"
## [26] "offset" "control" "method" "contrasts" "xlevels"
glm_house$coefficients
## (Intercept) median_income mean_rooms population
## 206855.817 82608.959 -9755.442 -3948.293결과해석
분석을 통해 소득 중앙값(median_income)이 주택 가격(median_house_value)에 가장 큰 영향을 미친다고 판단할 수 있습니다.
4.2 Random Forest Model
동일한 데이터를 랜덤포레스트(Random Forest) 방법을 적용하여 분석을 수행합니다.
- 데이터 로드 및 분리
library('randomForest')
names(train)
set.seed(1738)
train_y = train[,'median_house_value']
train_x = train[, names(train) !='median_house_value']
head(train_y)
## [1] 112500 65600 399200 47500 32500 200000
head(train_x)
## NEAR BAY <1H OCEAN INLAND NEAR OCEAN ISLAND longitude latitude housing_median_age population
## 4975 0 1 0 0 0 0.6437155 -0.7639971 1.0615750 -0.4728430
## 13918 0 0 1 0 0 1.7567501 -0.7078161 -0.7659165 -1.1262865
## 9020 0 0 0 1 0 0.3941562 -0.6890891 -1.5604781 10.1085264
## 2900 0 0 1 0 0 0.2793589 -0.1225970 0.5053819 -0.8375351
## 2764 0 0 1 0 0 1.8416002 -1.2649446 -1.0837411 -1.2137066
## 5786 0 1 0 0 0 0.6586891 -0.6890891 -1.1631973 0.2256351
## households median_income mean_bedrooms mean_rooms
## 4975 -0.6605285 -1.36479701 0.09416648 -0.79519952
## 13918 -1.1600972 -0.39249525 0.11519417 -0.02182537
## 9020 8.9751328 2.18074620 -0.11499230 0.93189653
## 2900 -1.1993304 -1.03071303 -0.47625410 -1.01131583
## 2764 -1.2542568 0.07902268 2.59860572 2.00915618
## 5786 1.0604990 0.01828013 -0.10923682 -0.54183837- 학습 및 모델 생성
아래는randomForest함수를 이용하여 train 데이터를 학습하는 단계입니다.ntree: 학습시 생성시키는 나무의 개수importance = TRUE: 변수 중요도, 정확도와 노드 불순도 개선에 얼마만큼 기여하는지로 측정
#some people like weird r format like this... I find it causes headaches
#rf_model = randomForest(median_house_value~. , data = train, ntree =500, importance = TRUE)
rf_model = randomForest(train_x, y = train_y , ntree = 500, importance = TRUE)- 모델 인자 확인
names(rf_model) #these are all the different things you can call from the model.
## [1] "call" "type" "predicted" "mse" "rsq"
## [6] "oob.times" "importance" "importanceSD" "localImportance" "proximity"
## [11] "ntree" "mtry" "forest" "coefs" "y"
## [16] "test" "inbag" - 변수 중요도 확인
rf_model$importance
## %IncMSE IncNodePurity
## NEAR BAY 462029976 1.590779e+12
## <1H OCEAN 1688587147 4.373630e+12
## INLAND 3977727665 2.923833e+13
## NEAR OCEAN 544439936 2.447774e+12
## ISLAND 1720896 7.325384e+10
## longitude 6763878133 2.568861e+13
## latitude 5348333153 2.226274e+13
## housing_median_age 1117409514 1.005488e+13
## population 1079150902 7.652526e+12
## households 1190484711 7.960279e+12
## median_income 8275173486 7.375662e+13
## mean_bedrooms 458284228 7.588929e+12
## mean_rooms 1765549887 2.032265e+13위 결과에서 평균 제곱 오차(Mean Squared Error, MSE) 가 포함된 %IncMSE는 변수 중요도의 척도입니다.
주어진 변수가 섞일 때, 예측의 평균 제곱 오차(MSE) 의 증가를 측정하여 모델의 변수 중요성에 대한 지표로 사용됩니다. 따라서 더 높은 숫자는 더 중요한 예측 변수입니다.
- The out-of-bag (oob) error estimate
Random Forest에서는 검증 데이터 오류 추정을 위해 교차 검증 이나 별도의 검증 데이터를 만들지 않습니다. 내부적으로 원래 데이터(original data)의 샘플링으로 분석이 진행되며, 샘플링 시 약 1/3의 데이터는 해당 차수(n-th) 트리 구성에는 사용되지 않습니다.
oob_prediction = predict(rf_model) #leaving out a data source forces OOB predictions
train_mse = mean(as.numeric((oob_prediction - train_y)^2))
oob_rmse = sqrt(train_mse)
oob_rmse
## [1] 49148.28위와 같이 예측값(oob_prediction)과 실제값(train_y)의 차이의 제곱으로 MSE를 구할 수 있으며, train_mse의 루트 계산(sqrt)을 통해 RMSE를 구할 수 있습니다.
sqrt(mean(rf_model$mse))
## [1] 50071.58
randomForest함수의 결과에서도 MSE 계산 값을 제공하고 있으며, 아래와 같이 확인 가능합니다.
(두 값의 차이에 대해서는 산출 식의 차이가 있는 것으로 추측되며, 추가 확인이 필요할 것 같습니다.)
- 테스트 데이터에 모델 적용
test_y = test[,'median_house_value']
test_x = test[, names(test) !='median_house_value']
y_pred = predict(rf_model , test_x)
test_mse = mean(((y_pred - test_y)^2))
test_rmse = sqrt(test_mse)
test_rmse
## [1] 48273.99결과해석
테스트 데이터에 모델을 적용해 본 결과 RMSE(oob_rmse)는 48273.99_로 모델 생성시 측정된 _49148.28 보다 조금 낮게 나타난 것을 확인하였습니다.
Step 5. 향후 개선 방향(Next Steps)
위에서는 데이터를 정리하고 기계 학습 알고리즘을 R에서 실행하는 기본 사항을 다뤘습니다. 그러나 의도적으로 남긴 개선 여지가 있습니다.
모델을 개선하는 확실한 방법은 더 나은 데이터를 제공하는 것입니다. 변수들을 다시 한번 살펴보면서 의미있는 변수 생성이 가능할지 생각해 보겠습니다.
longitude: 위도latitude: 경도housing_median_age: 주택 나이(중앙값)total_rooms: 전체 방 수total_bedrooms: 전체 침실 수population: 인구households: 가구median_income: 소득(중앙값)median_house_value: 주택 가격(중앙값)ocean_proximity: 바다 근접도
결과 개선 방법에 대한 제안
R 기술을 사용하여 새로운 데이터를 만들어 보세요!
한 가지 제안은 위도(longitude)와 경도(latitude)를 가공하여 '100만 명의 사람들과 가장 가까운 도시까지의 거리' 또는 '다른 위치 기반 통계'와 같은 것을 찾는 것 입니다. 이것을 피처 엔지니어링(Feature Engineering)이라고 하며 데이터 과학자들은 이를 효과적으로 수행하기 위해 많은 시간을 투자합니다.
또한 분기를 설정하고 다른 모델을 시도하여 설정한 Random Forest 벤치 마크보다 개선되는지 확인할 수 있습니다. 전체 목록이 아니라 출발점입니다.
트리 기반 방법 :
- gradient boosting -
library(gbm) - extreme gradient boosting -
library(xgb)
- gradient boosting -
다른 재미있는 방법 :
- support vevtor machines -
library(e1071) - neural networks -
library(neuralnet)
- support vevtor machines -
하이퍼 파라미터 및 그리드 검색
모델을 튜닝 할 때 다음으로 걱정해야 할 것은 하이퍼 파라미터 입니다. 이 모든 것은 모델을 초기화 할 때 모델에 전달하는 다른 옵션입니다. 즉, Random Forest 모델의 하이퍼 매개 변수는 n_tree = x 였고 x = 500 을 선택했지만 x = 2500, x = 1500, x = 100000 등을 시도할 수 있었습니다.
그리드 검색(Grid Search) 은 하이퍼 파라미터의 최상의 조합을 찾는 일반적인 방법입니다. 기본적으로 여기에서 매개 변수 세트를 모두 조합하고 각 세트에 대해 교차 검증을 실행하여 어느 세트가 최상의 예측을 제공하는지 확인합니다. 대안은 무작위 검색(Random Search) 입니다. 하이퍼 파라미터의 수가 많으면 전체 그리드 검색의 계산 부하가 너무 많을 수 있으므로 임의 검색(Random Search) 은 조합의 하위 집합을 가져와 임의 샘플에서 가장 좋은 조합을 찾습니다. 이 기능은 for-loop 또는 두 개를 사용하여 쉽게 구현할 수 있으며 이러한 작업을 도와주는 다양한 패키지도 있습니다.
필요하다면 R패키지 중 caret 패키지를 확인해 보세요. 최고의 매개 변수에 대한 그리드 검색과 같은 것들을 능률화하는 훌륭한 기능을 제공해 줍니다.
▶ 전체 코드 확인 : Github 링크
