

해당 포스트에서는 메일(mail)이나 문자 서비스(sms)에 사용되는 스팸 필터링(Spam Filtering) 기술에 대해 소개합니다.

INTRO
스팸 필터링(Spam Filtering)은 전통적인 텍스트 분석 문제 중 하나로, 일상에서는 스팸 메일 분류, 스미싱 문자 분류 등에 적용되어 쉽게 사용되고 있습니다. 이러한 서비스들에 '
[참고] 스팸 필터링(Spam Filtering)에 대한 이론이아닌 R코드가 궁금하신 분은 아래 링크를 참고해 주세요.

스팸 필터링(Spam Filtering) 적용 기술
스팸 필터링(Spam Filtering)은 사용자에게 비인가된 광고나, 도배성 메시지 등의 스팸 메시지를 걸러내는 기술입니다. 일반적으로 자연어 처리 기술(NLP, Natural Language Processing)이 활용되며, 크게 두 가지 방법으로 나누어 집니다.
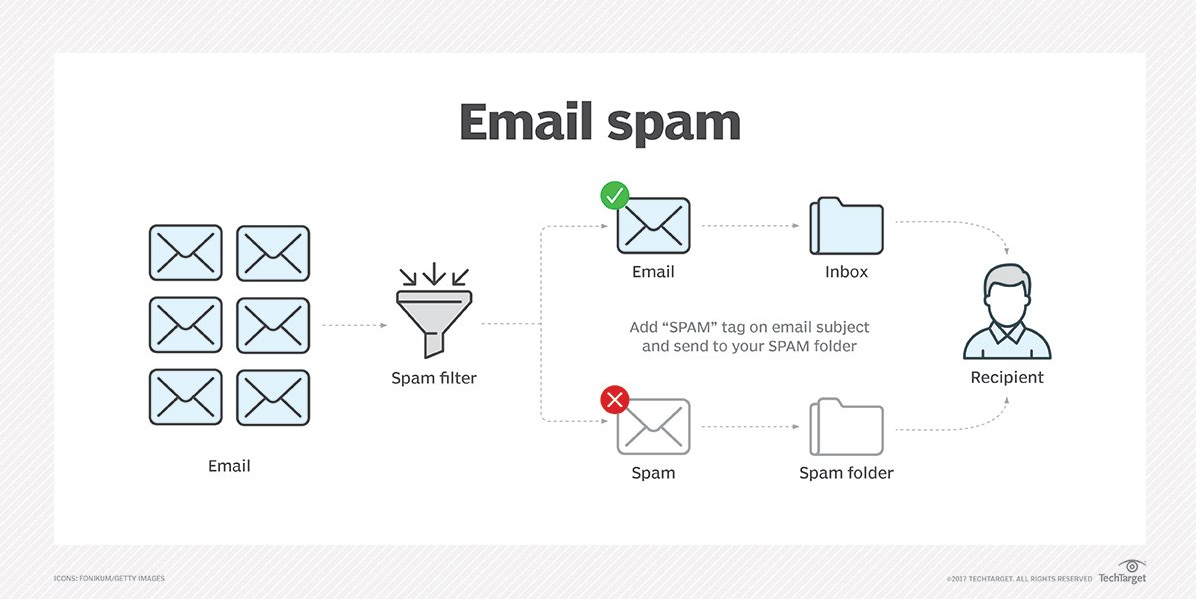
첫 번째 방법은
예를 들어, "당첨", "대출", "할인" 등의 단어가 메시지에 포함되어 있다면 이를 스팸으로 판단합니다.
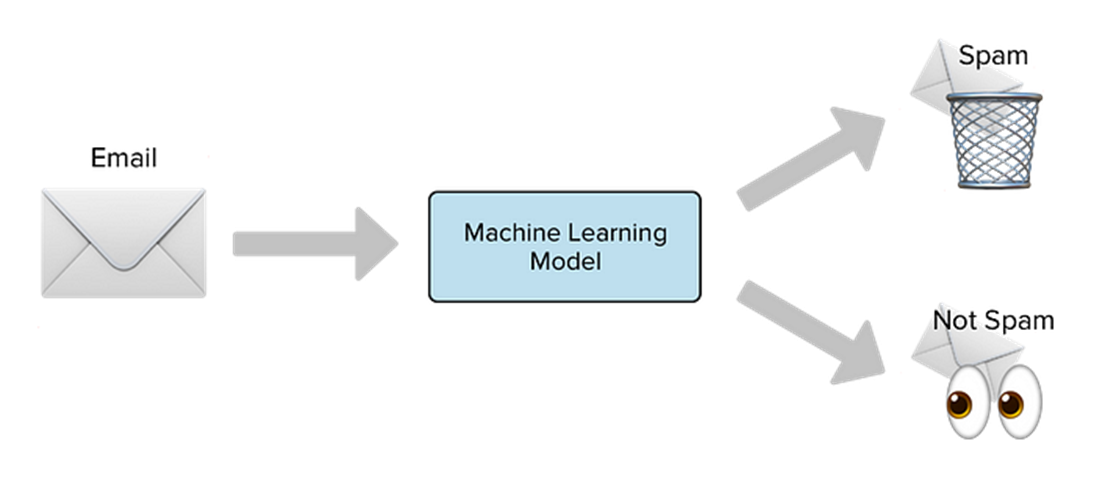
두 번째 방법은
예를 들어, 특정 단어나 문구가 메시지에 포함되어 있는 경우, 이를 특징(feature)으로 추출하고, 이를 이용해 스팸 여부를 판단합니다.
머신러닝 기반 스팸 필터링
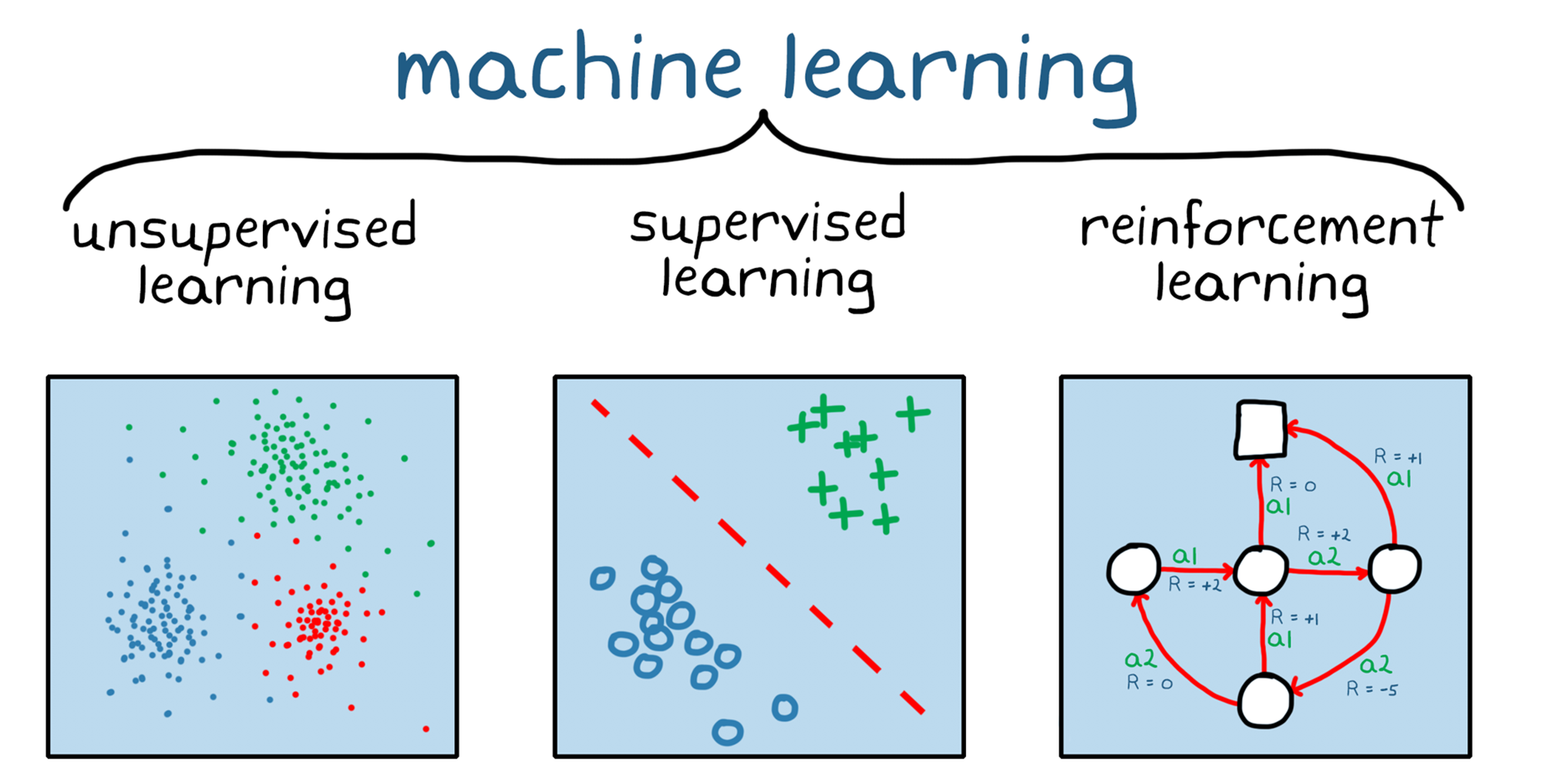
머신러닝 기반 필터링은 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)으로 구분됩니다. 지도 학습에서는 사전에 '레이블이 달린 데이터(labeled data)'를 이용해 모델을 학습하고, 비지도 학습에서는 '레이블이 없는 데이터(unlabeled data)'를 이용해 모델을 학습합니다.
지도 학습(Supervised Learning)
- 입력 데이터와 정답 데이터를 함께 학습하여 모델을 학습하는 방법
- 입력 데이터와 정답 데이터 사이의 관계를 학습하여 새로운 입력 데이터에 대한 예측 값을 생성할 수 있음
- 분류, 회귀 등의 문제를 해결할 때 사용됨
비지도 학습(Unsupervised Learning)
- 입력 데이터만을 사용하여 모델을 학습하는 방법
- 입력 데이터의 특성이나 구조를 파악하거나, 데이터 간의 군집화를 수행하는 등의 작업에 사용됨
- 군집화, 차원 축소 등의 문제를 해결할 때 사용됨
대표적인 기계학습 알고리즘
스팸 필터링에서 사용되는 대표적인 기계학습 알고리즘으로는 의사결정나무(Decision Tree), 나이브 베이즈(Naive Bayes), 로지스틱 회귀(Logistic Regression), 신경망(Neural Network) 등이 있습니다. 이 중에서도
의사결정나무(Decision Tree)
- 데이터를 분류하기 위한 트리 구조의 모델
- 데이터의 특성에 따라 가장 중요한 특성을 기준으로 분할하여 하위 노드로 이동하며, 이를 반복하여 최종적으로 분류를 결정함
- 해석이 용이하고 직관적인 모델이지만, 과적합(overfitting)되기 쉬움
- R 패키지 종류 : rpart, tree, party, randomForest, rpart.plot 등
나이브 베이즈(Naive Bayes)
- 베이즈 정리를 이용한 확률 기반 모델
- 각 특성(feature)들이 독립적이라는 가정하에, 주어진 데이터가 특정 클래스(class)에 속할 확률을 계산하여 분류함
- 간단하고 빠른 속도로 학습과 예측이 가능하지만, 독립적이지 않은 특성들이 포함된 데이터에는 성능이 떨어질 수 있음
- R 패키지 종류 : e1071, klaR, naivebayes, bnlearn 등
로지스틱 회귀(Logistic Regression)
- 데이터를 분류하기 위한 선형 모델
- 입력 데이터와 가중치(weight)의 곱의 합을 로지스틱 함수에 대입하여 0~1 사이의 확률값으로 변환함
- 확률값을 이용하여 분류를 결정하며, 이진 분류(binary classification)에 주로 사용됨
- R 패키지 종류 : glm, lrm, logistf, caret 등
신경망(Neural Network)
- 인공신경망(ANN)을 기반으로 한 모델
- 입력층(input layer), 은닉층(hidden layer), 출력층(output layer)으로 구성되며, 각 노드는 입력값과 가중치의 곱의 합을 활성화 함수(activation function)에 대입하여 출력값을 계산함
- 다양한 구조와 활성화 함수를 사용하여 복잡한 모델을 구성할 수 있으며, 딥러닝에서 가장 많이 사용되는 모델 중 하나임
- R 패키지 종류 : neuralnet, nnet, caret, MXNetR, tensorflow 등
관련 링크
[1] [R] 인공신경망 활용 스팸 필터링 (Spam Filtering using neuralnet in R)
[2] [Kaggle] Spam Filter Dataset
